llms.txt in. Prompt on. Code out.
Примеры промптов для Document AI и Data APIs — для Claude, Cursor и вашей IDE.
PaperOffice llms.txt — integration in Claude and Cursor, no SDK theater.
- Paste llms.txt Into Claude, Cursor, or your IDE.
- State the intent What to build — or use a prompt from this page.
- Let it write the code The IDE delivers the working integration.
Document AI
Скопируйте промпт, вставьте его в Claude или Cursor — готово.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build me an invoice extractor that:
1. Uploads a PDF via POST /job (multipart, field file_1)
2. Uses model=premium, idp_collection=invoice, priority=900 (sync)
3. Reads every field from job_result.fields including its bbox array
4. Renders a verification view highlighting each value
at its bounding box position
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Extract invoice fields including position in the document.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Write a minimal script that:
1. Sends an image or PDF to POST /job (multipart, field file_1)
2. Uses ocr_mode=complete and priority=900 (sync)
3. Prints job_result.text
Modes: complete (+tables), grid (+bounding boxes), text (plain).
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Full text via POST /job (ocr_mode=complete).
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a splitter for large batch PDFs (up to 3000 pages):
1. POST /job with template=pdf_ai_split (multipart, field file)
2. naming_instruction=Dokumenttyp_Datum_Absender,
locale=de_DE, priority=900
3. List every entry of job_result.documents_created
(suggested_filename + page_range)
The AI detects document boundaries automatically.
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Detect document boundaries and name output files.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Also use llms-full.txt for anonymize parameters (scenario, apply).
Build a GDPR anonymizer (preview → apply):
1. POST /job/add/workflow template=document_anonymize_preview (field file)
2. Set scenario=gdpr_auskunft (or externe_weitergabe / finanzdaten),
redact_categories=all, optional whitelist / custom_redact
3. client_wait=false then poll GET /job/get/{job_id}
4. Show detected_pii.redact_box_ids + simplified_boxes
5. Apply: POST /job/add/paperoffice_dataripper___redact_image
with files + bounding_boxes + redact_boxes from the preview
(or MCP: po_anonymization_pii_detect → po_anonymization_redaction_apply
with preview_job_id)
Optional one-shot: REST template=document_anonymize OR MCP po_anonymization_anonymize
(no HITL; pass scenario/whitelist).
Redact Agent: POST /documents/redact-agent-run or MCP po_documents_redact_agent_run.
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Detect and redact names, IBAN, addresses.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a text-to-speech generator:
1. POST /job with text=..., voice=Nadja, output_format=mp3
2. output=url and priority=999 for a synchronous audio link
3. Play or download job_result.audio_url
Voices: Nadja, Thomas, Anna, Hans (DE) + 100+ more.
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Sync MP3 via voice=Nadja (and more).
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a contract extractor that:
1. Uploads a PDF via POST /job (multipart, field file_1)
2. Uses model=premium, idp_collection=contract, priority=900 (sync)
3. Reads parties, dates, notice_period from job_result.fields
including each field's bbox array
4. Renders a verification view with bounding boxes
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Extract contract fields including position in the document.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build an e-signature request flow:
1. Ensure the document has a pofid in PaperOffice
2. POST /signatures/create with document_pofid (or pofid)
and a signers array (name + email per signer)
3. Return the signature request id and status
4. Optionally POST /signatures/remind for pending signers
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Invite signers and manage status/reminders.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a secure document delivery (digital registered mail):
1. POST /document_delivery/create_and_send with:
pofids: ["POFID_HERE"],
recipient_email, optional recipient_name,
subject, optional message
2. security_mode=link → PDF password in the same email
security_mode=secure_sms → link by email, password by SMS
(requires recipient_phone in E.164, e.g. +49170…)
3. Show delivery_id and that access events are logged
(Versandhistorie / delivery log)
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Secure delivery with PDF password (email or SMS) and delivery log.
Data & Security APIs
Geocoding, Weather, Fingerprint, VAT и другое — в виде промптов.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a geocoding helper that:
1. Forward: GET /geocoding/forward?q=...&lang=de
2. Reverse: GET /geocoding/reverse?lat=...&lon=...
3. Autocomplete: GET /geocoding/autocomplete?q=...
4. Prints display_name, lat, lon and credits_billed
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Address ↔ coordinates.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a weather lookup that:
1. Calls GET /weather/current?lat=...&lon=...&lang=de
2. Shows temperature, condition text and air quality if present
3. Displays credits_billed from the response
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Current weather including billing.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build an IP intelligence client that:
1. Calls GET /ip2location/full (empty ip = visitor IP)
2. Extracts country, city, geo_lat/lon, ISP
3. Optionally chains weather from the same response
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Location from IP, optional weather.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a device fingerprint check that:
1. Collects client signals in the browser
2. POSTs to /fingerprint/identify
3. Returns visitor_id / confidence for fraud checks
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Visitor ID and confidence.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build an email risk checker that:
1. Validates an address via the Fake Email Detector endpoint
2. Flags disposable / role / invalid domains
3. Returns a clear allow/deny recommendation
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Disposable mail and risk score.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a VPN/proxy detector that:
1. Calls GET /ip2location/vpn?ip=...
2. Normalizes is_vpn, is_proxy, is_tor, is_datacenter flags
3. Shows a clear risk badge for the visitor
Auth: Authorization: Bearer po_ut_YOUR_API_KEY VPN, proxy, Tor, datacenter.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a VAT ID validator that:
1. Checks an EU VAT number via the VAT validator endpoint
2. Returns company name and address when valid
3. Handles invalid / not-found responses cleanly
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Validity and company data.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a currency converter that:
1. Calls the currency exchange endpoint (from, to, amount)
2. Shows rate and converted amount
3. Caches the last rate for the UI
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Conversion with live rate.
Для Claude, Cursor & Co.
Copy-paste промпты, которые реально работают
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Create a Python script that:
1. Takes a folder of invoice PDFs
2. Extracts all fields using POST /job with idp_collection=invoice
3. Returns bounding boxes for verification (bbox array)
4. Exports to CSV
Important: Use file_1 for uploads, model=premium.
Handle both sync (priority>=900) and async modes.
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Batch extraction with verification coordinates.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Help me set up the MCP Server for PaperOffice in Cursor.
I want to use Document AI directly in my IDE.
Show me:
1. How to configure the MCP connection (POST /mcp)
2. Available tools via tools/list
3. How to process documents from my workspace
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Connect MCP and process workspace documents.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Create a voice agent that:
1. Takes audio input (Speech-to-Text)
2. Processes the text
3. Generates audio response (Text-to-Speech)
Use POST /job with:
- TTS: voice=Nadja, output_format=mp3, output=url
- Use priority=999 for sync TTS response.
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Process speech input and reply with audio.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a fraud detection system that:
1. Checks device fingerprints
2. Validates IP geolocation
3. Detects suspicious patterns
Use the Security & Data AI endpoints.
These are instant APIs (no polling needed).
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Check device fingerprint and geo/IP signals.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Create a batch processor that:
1. Takes a folder of large PDFs (up to 3000 pages each)
2. Uses POST /job with template=pdf_ai_split
3. Uses naming_instruction for smart filenames
4. Handles async jobs with polling (priority<900)
Use locale=de_DE for German document types.
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Split folders of large PDFs asynchronously.
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a document classifier that:
1. Watches a folder for new PDFs
2. Uses OCR (POST /job, ocr_mode=complete) to extract text
3. Classifies into: invoice, contract, receipt, correspondence
4. Moves files to category subfolders
5. Logs results to classification_log.csv
Authenticate with: Authorization: Bearer po_ut_YOUR_API_KEY.
Priority=900 for sync response. OCR, classify, sort into subfolders.
End-to-End
Полные решения для реальных проблем
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build an accounts-payable pipeline:
1. Watch a folder for incoming invoice PDFs
2. Extract fields via POST /job (file_1, model=premium,
idp_collection=invoice, priority=900)
3. Flag every field with confidence < 0.9 for manual review,
including its bbox for the verification UI
4. Export vendor, total, date and IBAN as DATEV/Lexoffice CSV
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Загрузка PDF → AI-IDP + ограничивающие рамки → Валидация → Экспорт
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a contract analyzer:
1. Upload contracts via POST /job (file_1, model=premium,
idp_collection=contract, priority=900)
2. Extract parties, start_date, end_date and notice_period
from job_result.fields (each field includes a bbox)
3. Store the key terms in a knowledge graph
4. Alert me 90 days before a notice period expires
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Загрузка контракта → Ключевые термины → Knowledge Graph → Оповещения
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a PDF converter service:
1. POST /job with field file_1 and
target_format=word | powerpoint | pdfa | webp
2. priority=900 for a synchronous response
3. Return job_result.output_url as the download link
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Загрузка PDF → Выбор формата → Конвертация → Скачать
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
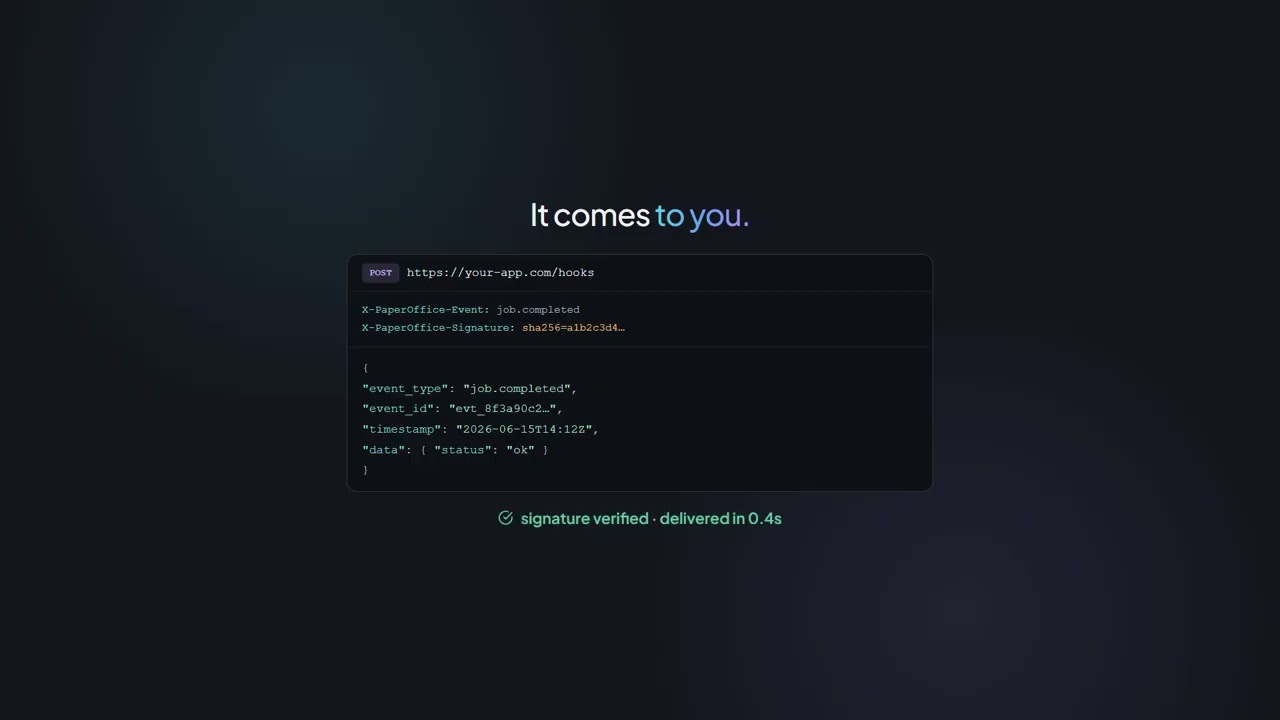
Build a webhook event handler:
1. Register a webhook via POST /webhooks
(url, events: job.completed + job.failed, secret)
2. Verify the X-PaperOffice-Signature header
(HMAC SHA-256) on every delivery
3. Process job_result whenever job.completed arrives
Note: webhooks always require a token (account binding).
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Регистрация Webhook → Отправка документа → Получение события → Обработка
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a document-to-audio pipeline:
1. OCR via POST /job (file_1, ocr_mode=complete, priority=900)
2. Split job_result.text into 5000-character chunks
3. TTS per chunk: POST /job (text, voice=Nadja,
output_format=mp3, output=url, priority=999)
4. Save all job_result.audio_url entries as a playlist
Auth: Authorization: Bearer po_ut_YOUR_API_KEY OCR документа → Подготовка текста → Генерация TTS → Сохранение аудио
Prompt
Read this llms.txt (AI-optimized API docs):
https://api.paperoffice.ai/latest/docs/llms.txt
Build a batch OCR-to-CSV exporter:
1. Scan a folder for PDF/PNG/JPG/TIFF/WEBP files
2. For each file: POST /job (file_1, ocr_mode=complete,
priority=900)
3. Collect filename, page_count, text preview and confidence
4. Write everything to ocr_results.csv
Auth: Authorization: Bearer po_ut_YOUR_API_KEY Сканировать папку → Пакетный OCR → Собрать текст → Экспорт в CSV
Продолжить с API
llms.txt и Playground — без лишних шагов.